数学@ふたば保管庫 [戻る]
|
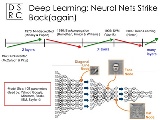
層を深くするとback propagationによる誤差伝播が指数関数的に減衰するから、学習の効果がほとんど現れなかったらしい。 層を深くしても問題なくなったのは、新たな手法が発見されたのではないだろうか。 |
|
無駄が増える |
|
>層を深くするとback propagationによる誤差伝播が指数関数的に減衰するから、学習の効果がほとんど現れなかったらしい。 >層を深くしても問題なくなったのは、新たな手法が発見されたのではないだろうか。 でも今のDeep Learningもバックプロパゲーション使っているんじゃなかったっけ? |
|
ていうか常識的に考えてスコアをn因子の和で表したときに、 それぞれの因子が任意の値を取り得る(個々の因子に他と区別できる特徴が無い)だと たちまち同じスコアを表す2^n通りかそこらの組み合わせができてしまう そのうちの正解は1個ぐらいで残りのは収束したかに見えて実は過学習で、 新たなサンプルを入力したら速攻破綻する やみくもにニューロンを増やすより1因子1特徴量のが大事、 というのがこれまで |
|
>やみくもにニューロンを増やすより1因子1特徴量のが大事、 因子ってニューロンのこと? |
|
よくわからないがニューロンが少ないほうが効率的だったってことだろうか |
|
それだけアルゴリズムが改善されてきたってことだろう 去年話題になった5x5魔法陣の全解を思い出した http://resemom.jp/article/2014/03/03/17380.html |
|
しかしアルゴリズムの本質はback propagationから進歩していないんだろ? |